Showing 90 of 90on this page. Filters & sort apply to loaded results; URL updates for sharing.90 of 90 on this page
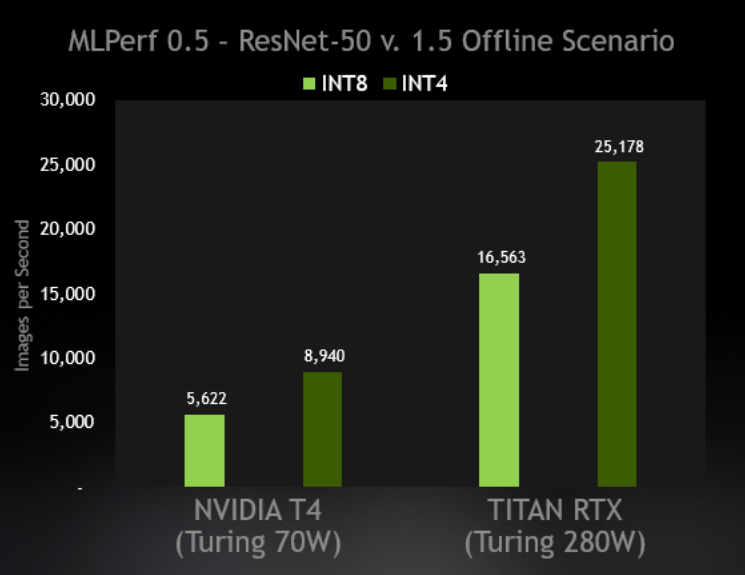
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3 | NVIDIA ...
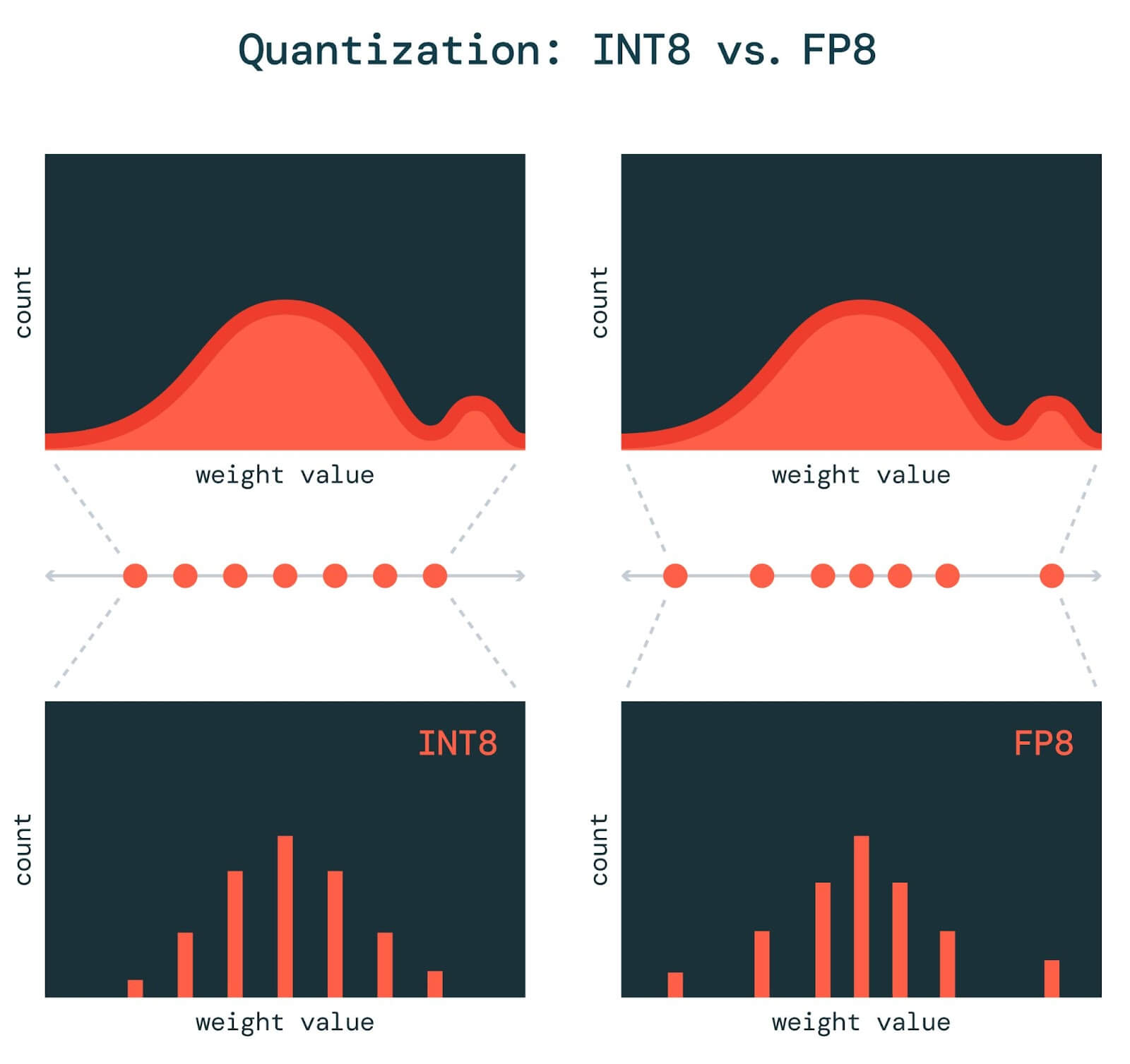
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
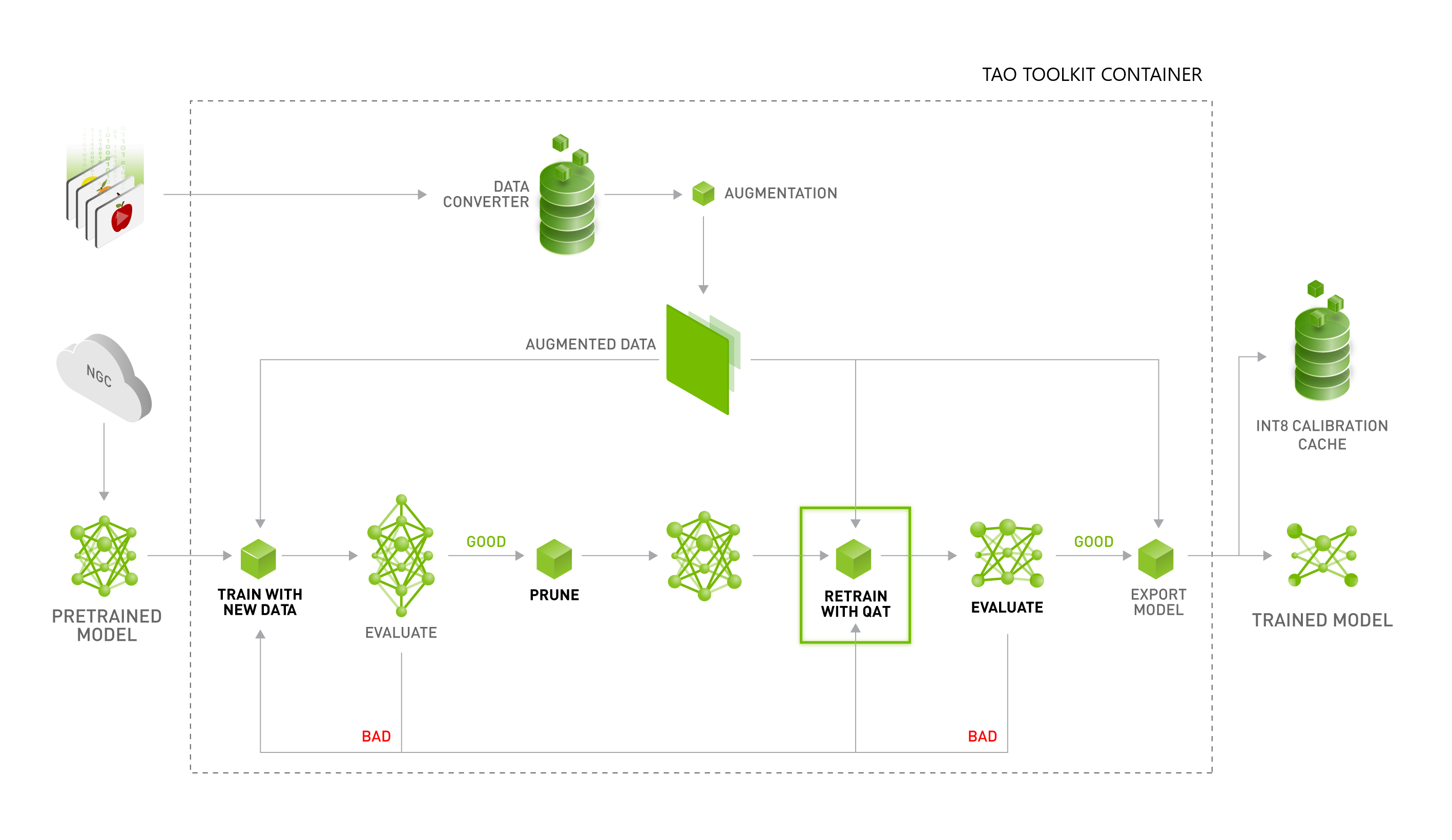
양자화 인식 학습 및 NVIDIA TAO Toolkit을 사용한 INT8 정확도 개선 - NVIDIA Technical Blog
7. TensorRT 中的 INT8 - NVIDIA 技术博客
Tag: INT8 | NVIDIA Technical Blog
利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - 广州市迈进信息科技有限公司/研云创服务器
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
NVIDIA TensorRT를 통한 양자화 인식 학습을 사용하여 INT8 추론에 대한 FP32 정확도 달성 - NVIDIA ...
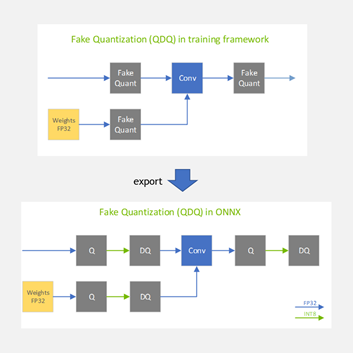
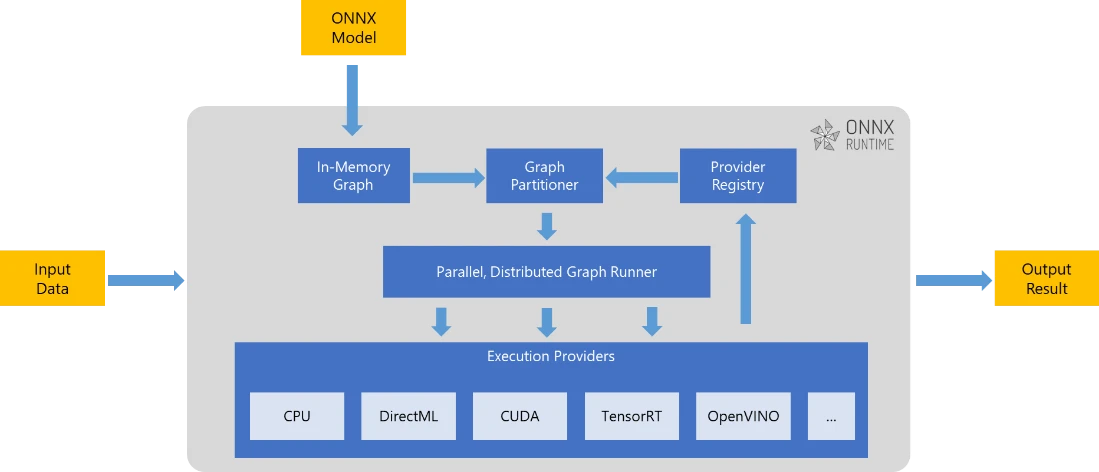
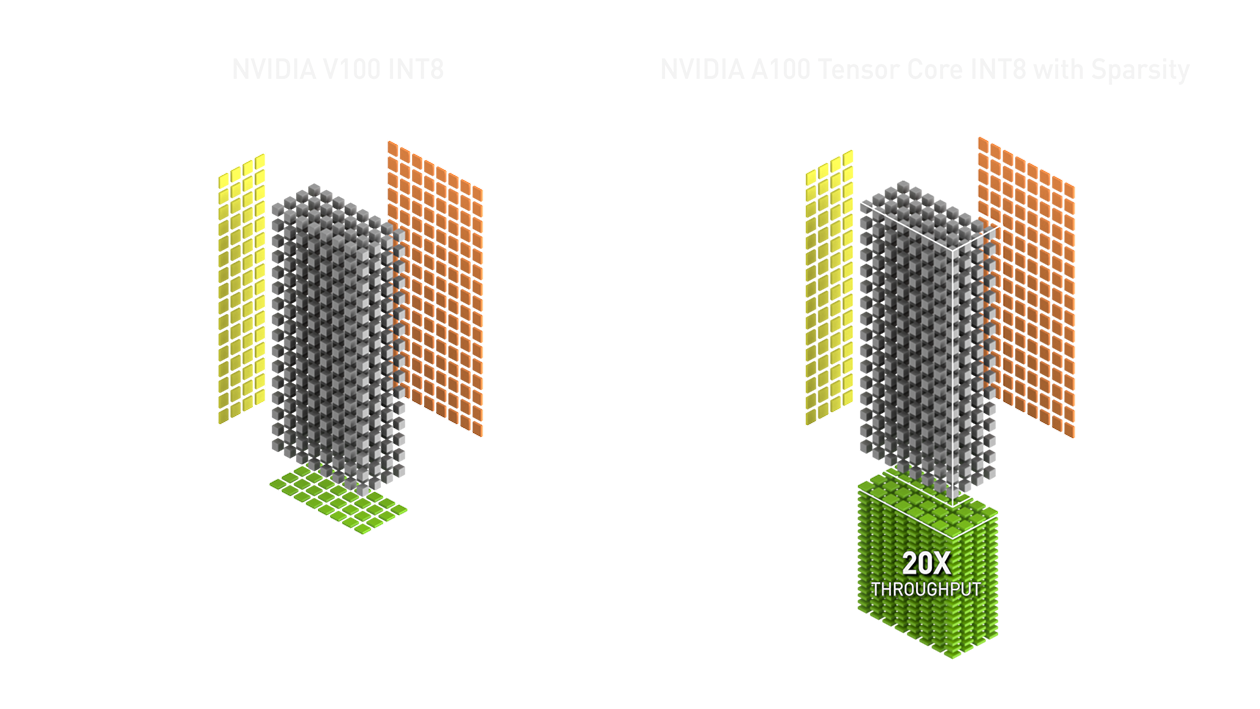
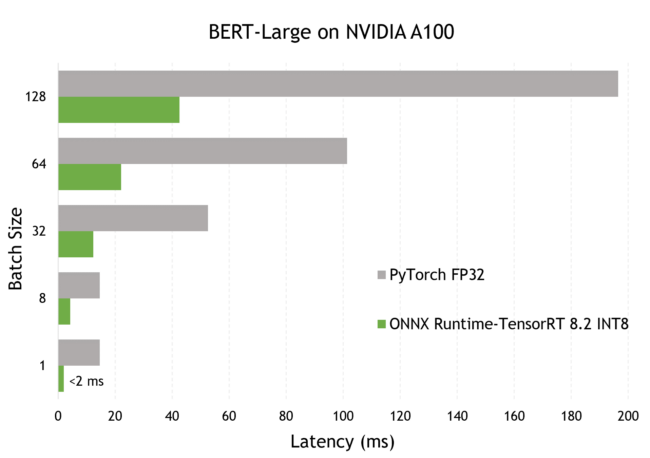
在 NVIDIA GPU 上使用 ONNX Runtime-TensorRT 优化和部署Transformer INT8 - 知乎
TensorRT 8.6.1.6 can't build engine with INT8 ONNX on NVIDIA GeForce ...
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
GTC 2020: Toward INT8 Inference: Deploying Quantization-Aware Trained ...
Tensor Core :通用于 HPC 和 AI | NVIDIA
NVIDIA GPU的INT8变革:加速大型语言模型推理_CPU_什么值得买
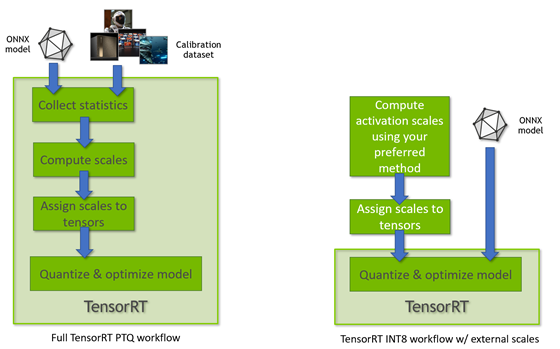
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
Optimizing and deploying transformer INT8 inference with ONNX Runtime ...
Improving INT8 Accuracy Using Quantization Aware Training and the ...
Accelerate Generative AI Inference Performance with NVIDIA TensorRT ...
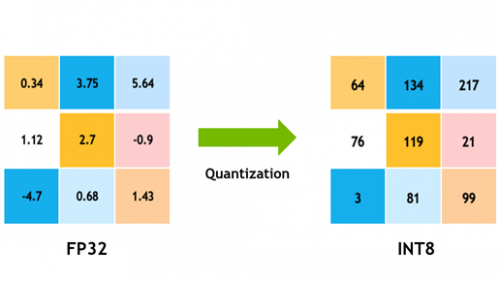
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
Int4 Precision for AI Inference | NVIDIA Technical Blog
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
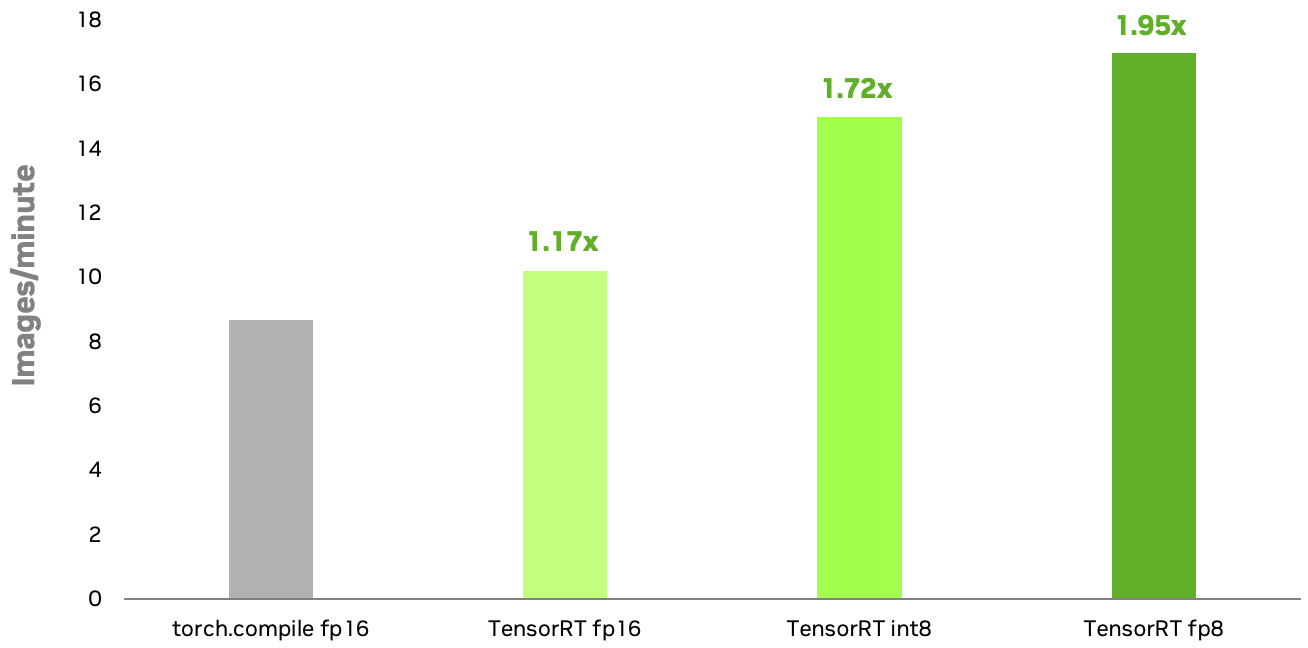
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...
Error Code 2: OutOfMemory Error during INT8 calibration - TensorRT ...
NVIDIA TensorRT 通过 8 位预训练量化将 Stable Diffusion 的速度提升近 2 倍 - NVIDIA 技术博客
Deep Learning Model Precision: FP32, BF16, INT8 and INT4 – Insights ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
Benchmark int8 similar to fp32 on yolov8 from ultralytics - Help Docs ...
Automatic Mixed Precision for NVIDIA Tensor Core Architecture in ...
Excuse me, does the 3060Ti graphics card support TensorRT int8 ...
INT8 Calibration Reduces Accuracy of PyTorch MNIST Model on Jetson Orin ...
How to provide calibration data for INT8 quantization with dynamic ONNX ...
NVIDIA H200 Tensor Core GPUs and NVIDIA TensorRT-LLM Set MLPerf LLM ...
NVIDIA TensorRT | NVIDIA Developer
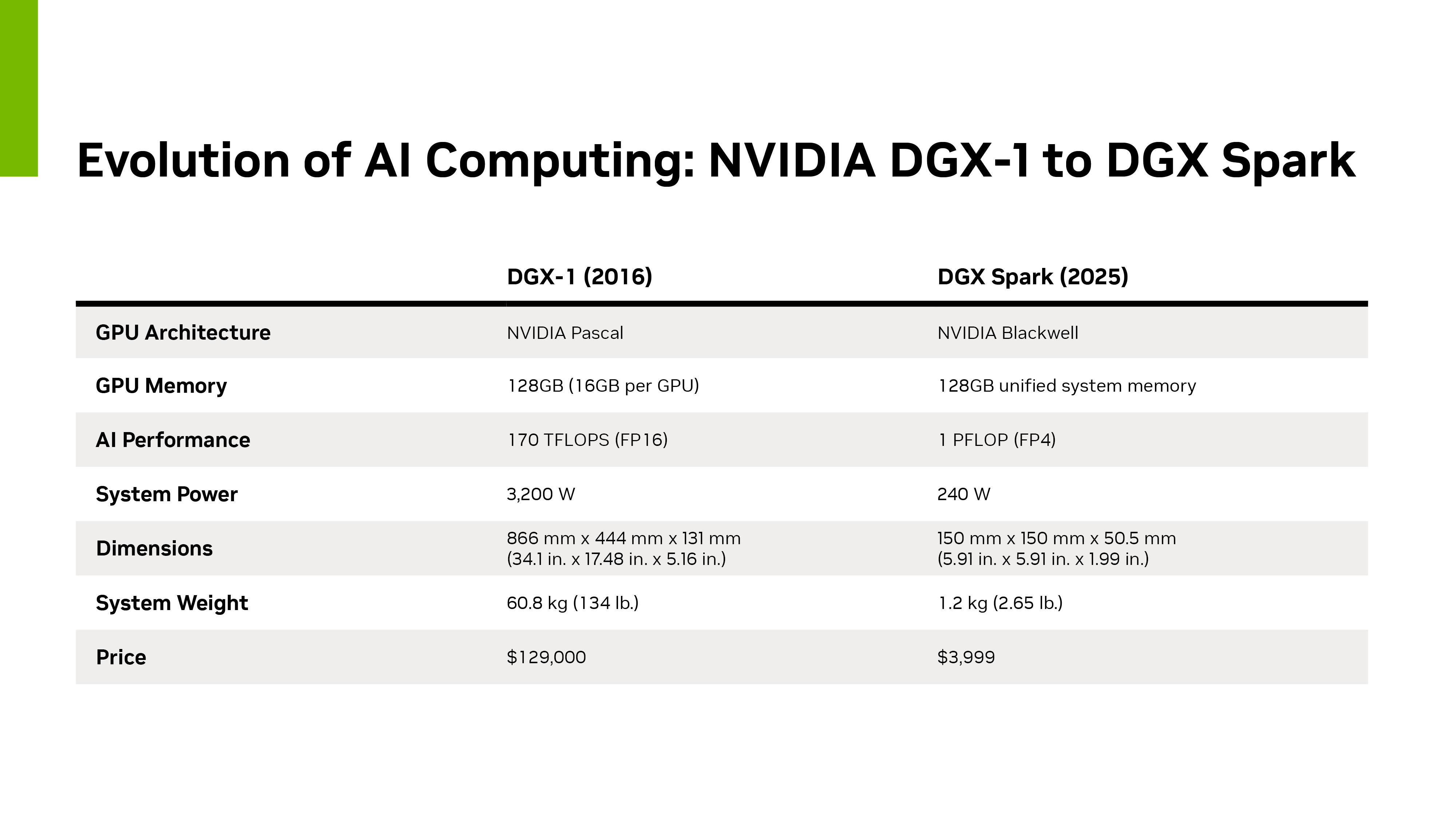
NVIDIA DGX Spark يصل إلى مطوري الذكاء الاصطناعي في العالم
Details about Int8 · Issue #4 · NVIDIA/TensorRT · GitHub
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
CUDA-CenterPoint INT8 inference performance · Issue #92 · NVIDIA-AI-IOT ...
DetectNet_v2 - NVIDIA Docs
how to check precision of each layer after quantize to INT8 model ...
INT8 中的稀疏性:NVIDIA TensorRT 加速的训练工作流程和最佳实践 - 知乎
INT8 quantization with same model and different weights · Issue #2705 ...
INT8 calibration for efficientdet · Issue #1498 · NVIDIA/TensorRT · GitHub
INT8 mode layer fusion · Issue #887 · NVIDIA/TensorRT · GitHub
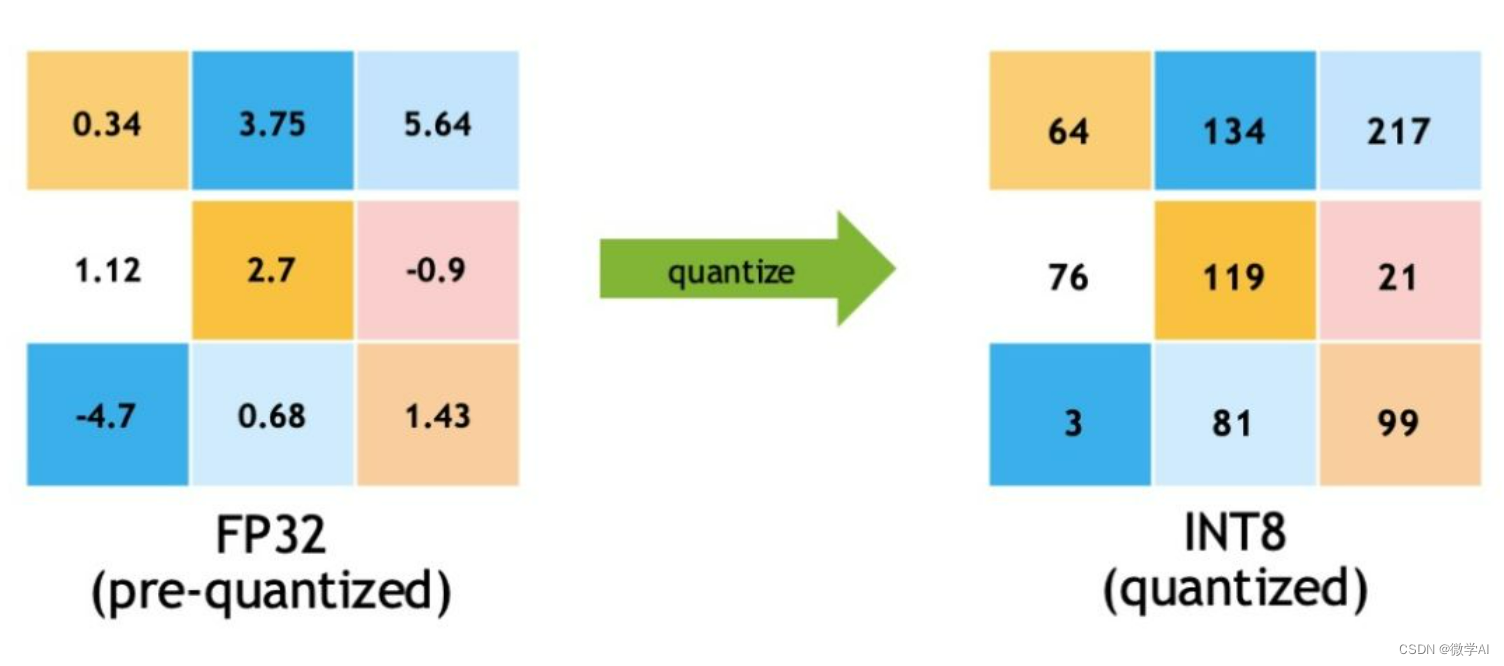
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
MNN CUDA支持int8推理,矩阵乘可提速一倍! - 知乎
第 11 章:AI 加速 | Jimmy Song
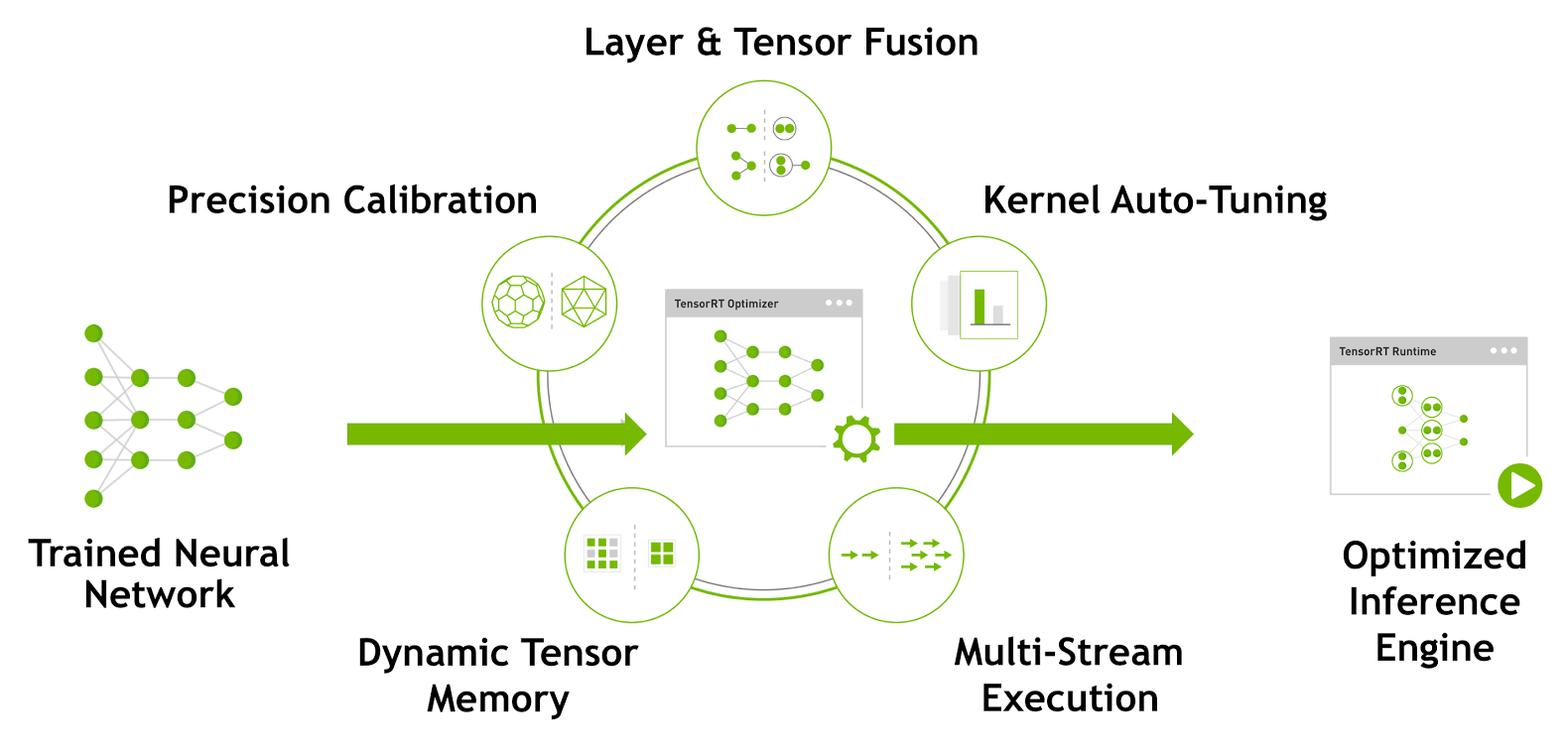
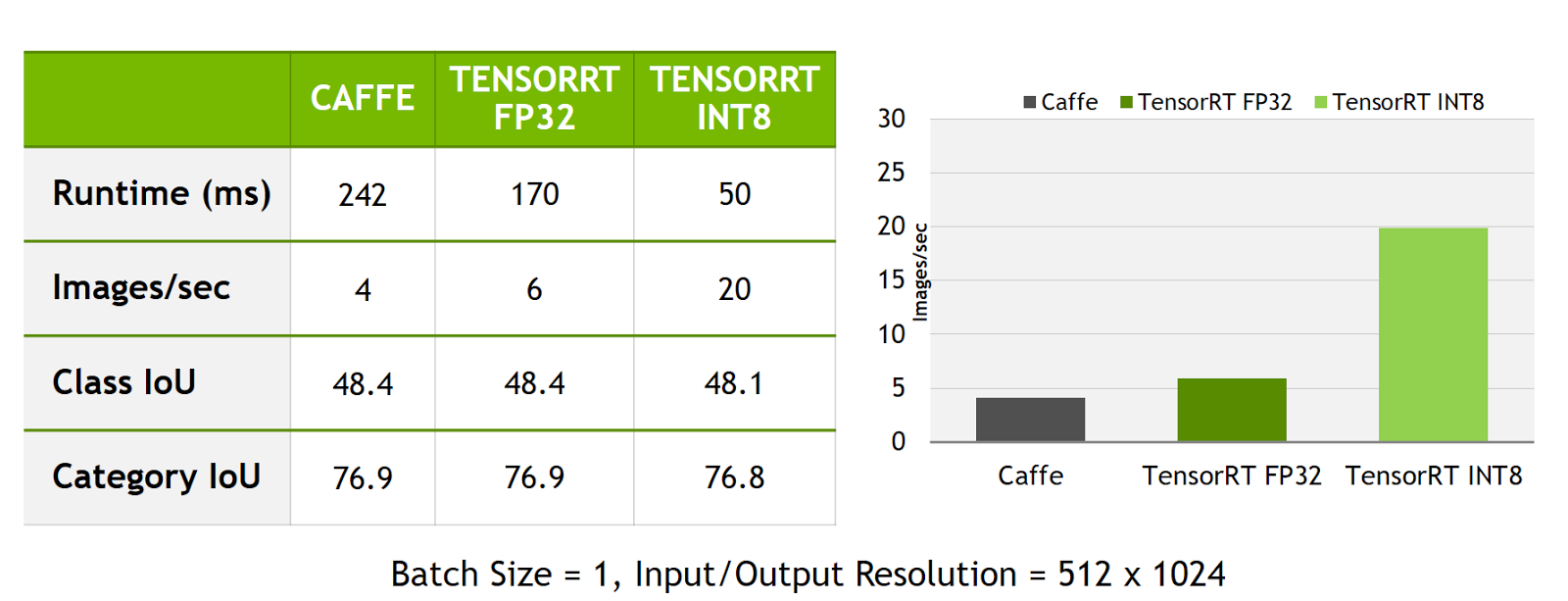






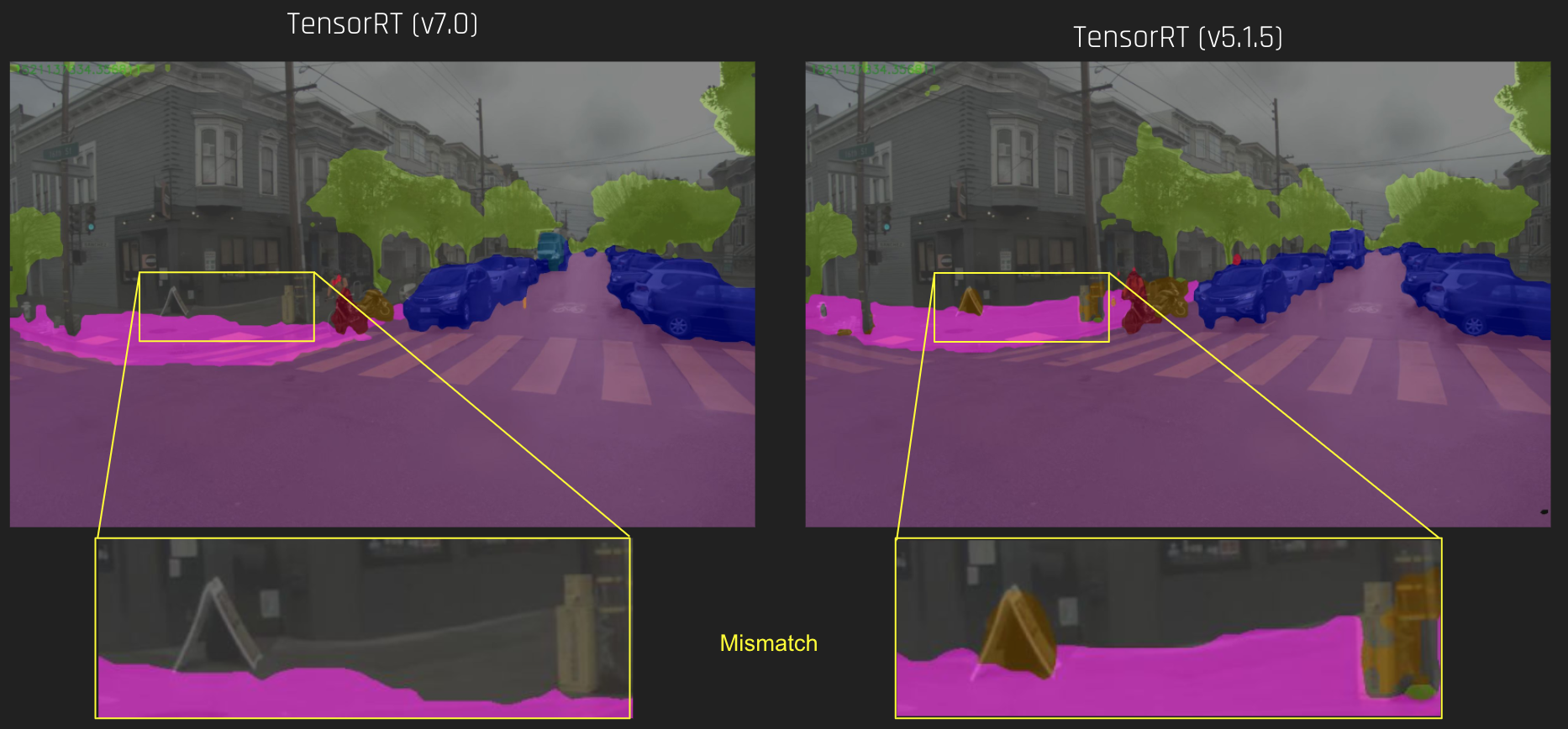

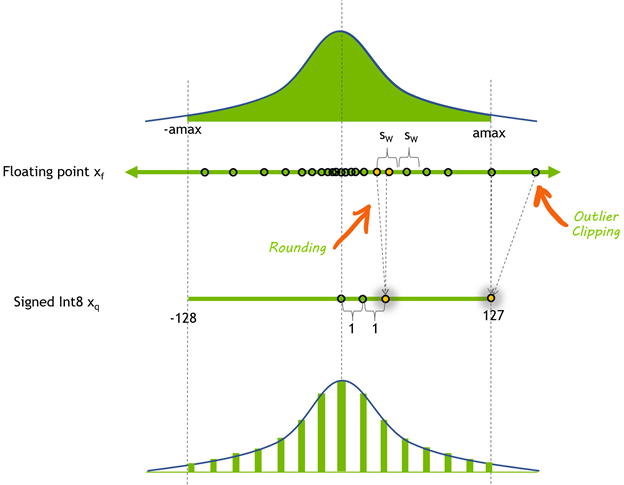























































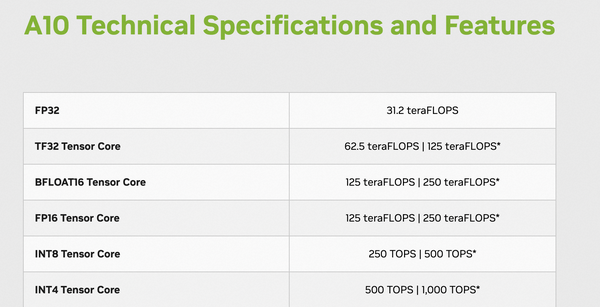
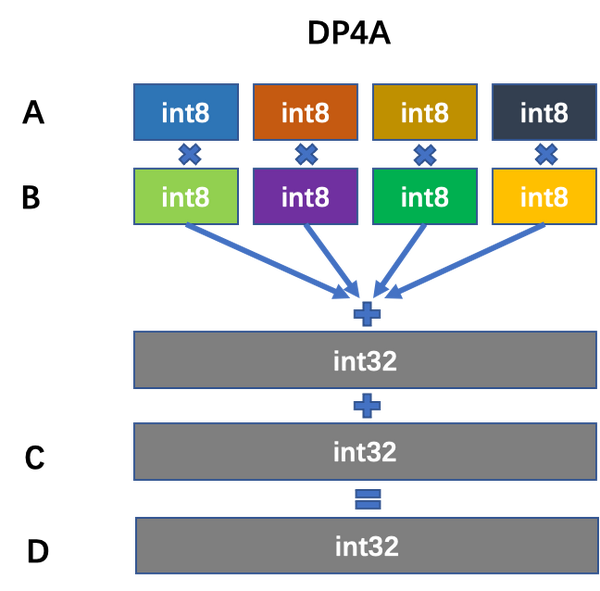
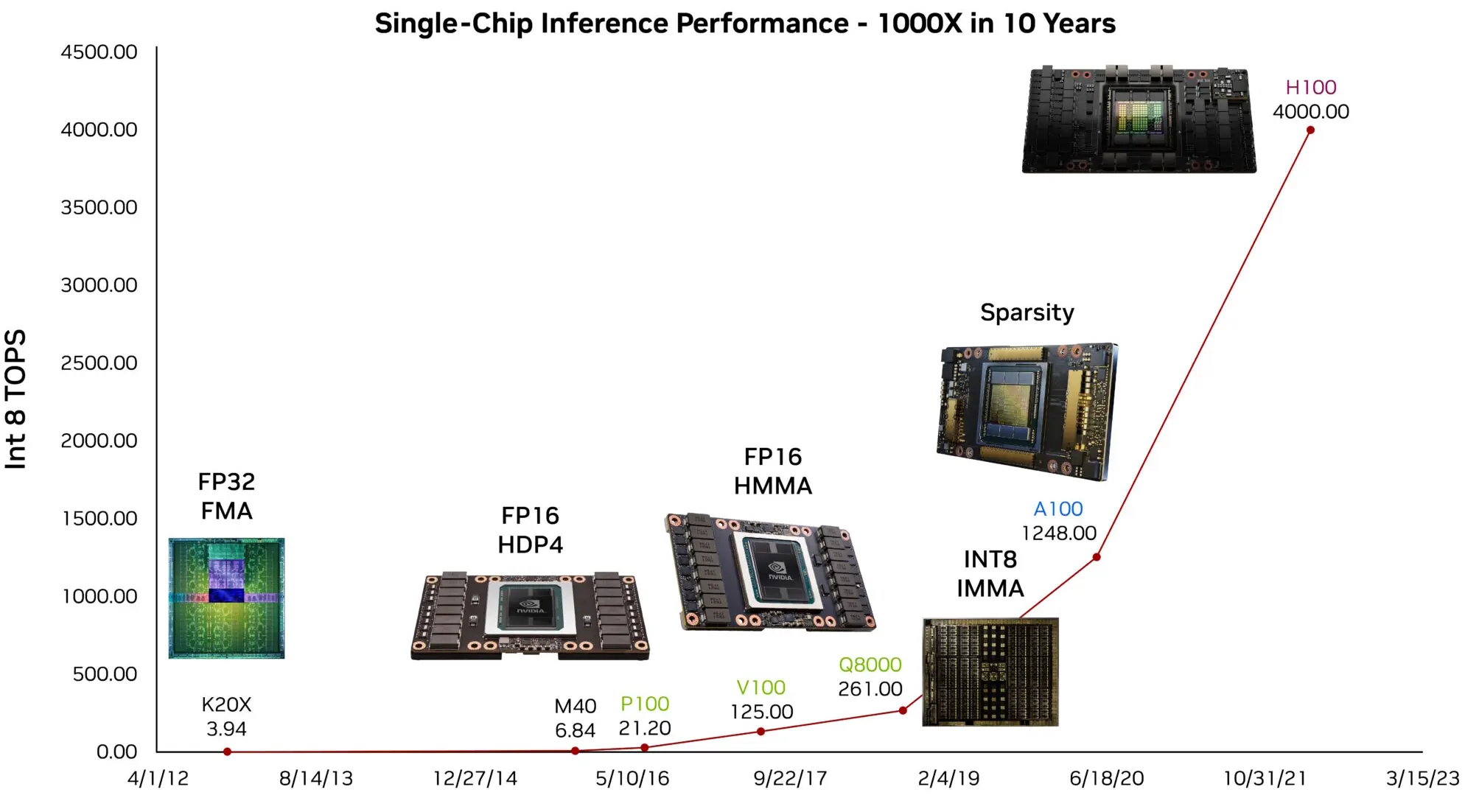
{kind=link}